

Cerebras shouldn't go public.

TLDR: that’s it. They shouldn’t be. The product is not remotely competitive. They will probably do poorly on the public markets after an initial surge in share prices based on sheep money following synchronized, carefully crafted but ultimately deceptive media buzz. If that happens, there is a risk of really promising and potentially critical IP falling into adversarial hands who then end up building what we really should be - the next great American chip company. Instead, they should take a down round, stay private and build a compelling product.
The rest of the article is for folks who want to get into the weeds on the data that supports these claims. I welcome all feedback - especially if you think I have made conclusions that are unsupported. The goal is to cut through the noise and reach ground truth.
The (social and tech) media halo around Cerebras is masking an inferior product offering and setting up expectations that are, quite frankly, impossible for Cerebras to meet. I listened to podcasts and interviews that regurgitated Cerebras’ marketing claims, read blogs and media articles, often shared by really popular accounts on X, all of which were saying that Cerebras was ready for primetime and a threat to the incumbents. Terrible things can happen when the perception of the company changes upon public market analysts’ scrutiny. There is a significant probability of the stock price tanking, allowing foreign adversary linked-PE firms to pick up the IP. It has happened before, for A123 (batteries) and Fisker Automotive (EVs), 10 years ago. Can you calculate the ROI for China, considering their acquisition of these pieces for tens of millions - in terms of how they have been able to build on top of it, combine their strengths, do more R&D, actually build a superior product - to where they stand today in the EV and battery market globally? Better than all VCs, I think.
If this was a SaaS company with no critical IP/knowhow, by all means, cash in and be rewarded for your early investment. But with companies in sectors we want to retain our edge (semiconductors, defense, etc) can we act more responsibly and understand that our actions have consequences? We are in a chip Cold War with China. We seem to perfectly understand that China is accelerating its innovation under restrictions, harnessing homegrown expertise throughout the semiconductor stack. Should Cerebras’ fail, the good parts of the IP portfolio would be a great leg-up to Chinese efforts, if they can get their hands on it. Yet we have no qualms pushing this clearly immature company of potentially strategic importance in the future to fend for itself on Wall Street. Maybe it is time to pause and think about national interest over the rush for liquidity?
I choose to face my fear of losing potential future friends in VC and hit publish. Let the chips fall where they may.
I have followed Cerebras for a long time. I wrote about them 4 years back, as an example of an idea whose time had come - a concept that had been tried before but failed because our semiconductor fabrication abilities were not good enough. The future had arrived.

I am not an investor in the company so I had to wait for the S-1 to learn more about the company other than what I knew from public sources. Cerebras has garnered fawning tech media coverage over the entirety of its existence (2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024), and been touted as an NVIDIA challenger.
The S-1 left me totally disillusioned. In fact, I couldn’t answer the following question with a definitive yes:
Does Cerebras have product-market fit?
And that is the key question we will try to answer.
Most coverage of Cerebras is filled with adulation at the technology and very rightfully so. Contrary Capital published a deep dive last year. The article does a great job of describing the fundamentals behind the idea that Cerebras was created on. By all measures, Cerebras is a wonder of electrical engineering. As a former electrical engineer I love everything about the concept. In fact, if I had seen Cerebras at their seed round, I would have invested a material portion of my hypothetical fund into the company, no questions asked.
Founder-market fit, 100%.
Technology with potential for market dominance, absolutely.
Great founding team, check.
But as the company raised more and more money, it seems like everyone lost themselves in the brilliance of the idea. It was too beautiful, too contrarian and too disruptive. So much so that we forgot to ask, but is it really working?
That is where we will start.
How do we know if something is working? When we see data about it.
No one has real data about Cerebras’ performance
Cerebras has never provided reliable data that allows you to directly compare performance under the same condition to other hardware. It is baffling that a $4B company trying to fight for a share of the AI market doesn't submit scores to benchmarks like MLPerf. How are your potential customers going to properly vet you? In the absence of proper benchmarked data, we end up with apples-oranges comparisons where we have to look at either blogs like Artificial Analysis saying that Cerebras is 10X faster at inference or Cerebras themselves saying it without providing full context.
What does this missing context entail? Exactly the things that would help a customer understand how the chip is likely to work for them! For example, dataset description (for distribution of input/output sequence lengths), number of wafers used and total throughput across different latency constraints.

(Side note: this will be a recurring theme, Cerebras’ choice of metrics to compare to other offerings is rather obtuse).
It probably takes 1 FTE worth of investment to make the submission for 1 benchmark. Why not choose the 2-3 most important benchmarks for your prospective customers and show how good you are? For context, Cerebras spent nearly 25M in 2022 and 20M in 2023 on SG&A. I would think it is worth the ROI to provide more data to prospective customers by spending 2-3% of total annual SG&A.
Cerebras said they would rather spend time working on customers problems than beating benchmarks that didn’t matter in the real world. I admire the conviction and the focus on customers. But I think the resulting lack of transparency, coupled with the high cost of Cerebras systems and the daunting thought of trusting a 4 year old startup (in 2019, when the quote was made) with your evolving computing needs has hurt Cerebras more than its purported focus on customers have helped. Clearly, nothing has changed in the next 5 years. Cerebras still doesn’t go to MLPerf. They are still spending money working on their customers' problems. Their potential customers, meanwhile, can’t stop spending 100s of billions of dollars buying chips from companies that do go to MLPerf. I do not think this is playing out as Cerebras said it would.
In fact, I would also speculate that showing up at MLPerf had a significant contribution in Habana’s acquisition by Intel - it can’t hurt that the leading players in the space are all unintentionally helping you in your due diligence when they cross-examine each others’ submissions! In the same vein, I would offer examples of MosaicML participating in the open division at MLPerf and then being acquired by Databricks. Graphcore was showing up at MLPerf religiously and then got very close to doing a deal with Microsoft. On the other hand, all the players struggling with proving their offerings to customers (Groq, Sambanova, Cerebras) somehow have been convinced that their sales and marketing dollars are better spent trying to convince customers with what I can only imagine is cherry-picked performance data at best.

Cerebras is very expensive for the performance it claims
Cerebras claimed “while GPU manufacturers may claim leadership in TCO, this is not a function of technology but rather the big bull horn they have.” They are right in their claim that TCO (total cost of ownership) of GPUs is not a function of the technology itself, but regardless, TCO is top of mind for their customers. I would love to speak with a customer who would say TCO is not their priority. And it is one metric where Cerebras is really struggling.
Let’s look at a simplified comparison. We will look at the WSE-3 product sheet.

Given that 1 WSE-3 has 52x more cores than NVIDIA H100, we will anchor to this number. For what it’s worth, I personally think “cores” is a meaningless metric. There is no equivalency in what is defined as a core for Cerebras and what it means for the other chip you choose to compare with. Keep in mind, additionally, WSE-3 is Cerebras’ latest offering, but H100 is NOT NVIDIA’s latest offering. 1 WSE-3 costs 2-3M - we will assume 2.5M.
Let’s now try to compare what I can offer to the customer who is deciding between Cerebras or DGX H100s. A DGX H100 has 8x H100s. In October, Cerebras released information saying that they can now hit 2100 token/s on Llama 3.1 70B model. This setup would cost a customer $10M (4 x $2.5M, not accounting for any peripherals).
According to Cerebras themselves, they estimate that the best you can expect from 1 DGX-H100 is 128 token/s. A DGX H100 unit costs $270k. This isn’t really a win. It simply means I can get to Cerebras speeds with about 17 DGX H100s, at a cost of $4.6M + peripherals, call it an even $5M. Mind you, this is without NVIDIA doing any optimisation that we have let Cerebras do (we are still using NVIDIA’s numbers as provided by Cerebras from their Hot Chips presentation).
If I get 2100 tokens/s from a setup of 4 WSE-3s, I can roughly say that each WSE-3 is driving 525 token/s. So compared to a DGX H100, I am only getting a 4X boost. At the same time, I am paying almost 10X more for the WSE-3. Where’s my 52x performance boost from 52x cores?
What about power, isn’t that important? Let’s do the math again.
4 WSE-3s will draw 92kW. To get the same token/s, I need 17 DGX H100s which will draw 108.8 kW. (17 x 6.4kW). If you ran at peak power, all day, all year, you would have about $25k extra power bills (16c/kwh) when owning NVIDIA over Cerebras. When you are saving $5M on capex upfront, I don’t think you will mind the extra $25k in electricity opex per year.
Can we agree on a metric that actually matters to the customer?
I propose it is performance/TCO.
Performance is what Cerebras’ customer (hyperscaler, for example) can charge their customer(an individual or enterprise user) for. TCO is a proxy for what the hyperscaler is spending.
Performance/TCO = (Delivered token/s to user)/TCO
In this case,
Cerebras = 2100/10 = 210 token/s/$M
NVIDIA 17 DGX H100s = 2100/5 = 420 token/s/$M
So tell me, what IS the value proposition, exactly?
Why does Cerebras not work as advertised?
From a purely first principles perspective, the reasoning is still scientifically solid. It’s plain physics, moving data around on chip, between co-located memory and compute, is faster!
What gives, then?
The answer lies in the difference between metrics that the chips are marketed with and the metrics that are truly important in driving the user experience. It does not matter as much if you are moving data around faster, if you can’t do the math operations with the data fast enough.
How fast are you at math?
The metric which tells us how fast you can do the math operation is flops. But there is a nuance which marketing teams from every hardware company have been taking liberty with. There is dense compute and sparse compute. Dense compute is the absolute amount of math that your chip is capable of. You are not skipping any step. You are doing all the matrix multiplications, even if the elements are zero. With sparsity, you start deploying algorithmic techniques that allow you to perform fewer operations because you focus on more meaningful calculations. You would also need to put in hardware elements that allow you to understand which are more meaningful calculations (indices for non-zero elements, for example). These decisions are tradeoffs: your chip having hardware that accelerates your sparse compute means it has less pure dense compute. You have traded pure throughput for speed on sparse workloads. The other tradeoff is loss of accuracy - the more “pruning” you do to run a sparse workload faster, the larger the hit to accuracy you have to endure. In summary, the chipmaker can create conditions where the highest flops you can get out of the system come out to be an artificially inflated number that doesn’t represent how fast they really are in the context of the customer. This reminded me of a joke in Big Bang Theory (seriously, hear it!). You will know shortly why this is timely.
WSE-2 had 7.5 petaflops of dense compute. When WSE-3 was announced, dense compute was dropped from the datasheet. Instead, we were told that WSE-3 packs 125 petaflops of “peak AI performance”. What’s “peak AI performance” and how does it relate to dense compute? What does this mean for the user?
The answer, I think, is hidden in this statement: “Cerebras remains the only platform that provides native hardware acceleration for dynamic and unstructured sparsity, speeding up training by up to 8x”. This is like the joke above. I speculate that this translates into “we can deliver 125 petaflops, but only under a specific workload that we choose, which will probably be different from your actual relevant workload you want to deploy.” For you, the user, it is actually 125/8 = 15.625 petaflops of dense compute. Whenever a customer doesn’t see pure dense compute being made available to them, they need to understand what is this speed coming at the expense of and whether it affects the ROI of their use case. This is probably a combination of suboptimal customer research, inaccurate needs forecasting and maybe, some bad luck on Cerebras’ part. In principle, it is a good idea to have circuit elements that allow you to skip unnecessary calculations. But the nature of workloads has evolved in ways where brute dense compute seems to be driving speed of training and inference much more than optimisations (at the cost of more dense compute) are.

One other way to reach the same conclusion is from this statement in the press release: “The WSE-3 delivers twice the performance of the previous record-holder, the Cerebras WSE-2, at the same power draw and for the same price.” In other words, they doubled the dense compute, from 7.5 to 15. There’s another hint, for those looking closely. WSE-2 was on TSMC’s 7nm node and WSE-3 was on the 5nm node. The number of transistors went from 2.6T to 4T. But the core count barely moved, from 850000 on WSE-2 to 900000 on WSE-3. Performance is up 100%, but core count increased by only 6%. Remember when I told you that “cores” is a meaningless metric? This is proof of that.
Now let’s look at Cerebras’ choice of comparison DGX H100 again. Here we see NVIDIA advertising 32 petaflops for a DGX H100. Again, this is a typical marketing claim. This translates to 16 petaflops of dense compute. So now if you peek beyond the marketing metrics, each WSE-3 has the same amount of compute as one DGX H100. This is not good news for Cerebras, because each DGX H100 is 1/8th the cost of a WSE-3. In a recent post, Cerebras again compared their “peak AI performance” of 125 petaflops to DGX B200’s 32 petaflops saying it is significantly faster. This is similarly misleading, because Cerebras is comparing their sparsest flops to NVIDIA’s densest.
In my assessment, when compared to Blackwell, Cerebras is only half as fast (15.6 PFLOPS vs 32 PFLOPS) at 5X ($2.5M vs $500k) the cost.
I took Cerebras’ comparison table and added a few more rows to it to reflect the difference.

The cells in shades of red are the literal red flags. It tells you two things. On a unit basis, Cerebras is a 100X more expensive than a H100. But more importantly, on a dense compute basis, you can buy (1/0.078 = ) 13X more compute per $ if you chose H100.
It gets worse.
If you do this for Blackwell, plug in 4 petaflops of compute for $35k a unit, now you can get 17.5X more compute per $ compared to WSE-3.
I will make a prediction. Wait until the NVIDIA customers get their hands on B200s, Cerebras’ claims will collapse when the performance data comes out.
How fast are you at moving data in and out of the wafer?
Missing from the WSE-3 datasheet is also a crucial contributor to speed - the interchip interconnect bandwidth. Now that models have gotten so large that they no longer fit on one WSE-3, the customer will need to use several WSE-3s. In this case, it doesn’t matter how fast data can move on each WSE-3, if data moves slowly between one and the next WSE-3 and is throttled by the bandwidth. On this metric, Cerebras is at 150 GB/s (look at system I/O on this page). NVIDIA’s latest NVLink shipping with Blackwell is at 1800 GB/s (12x higher). It is alarming that while NVLink’s specs have gone from 300 GB/s to 1800 GB/s in 5 years, Cerebras’ has been unable to break 150 GB/s. Stunningly, for the last 5 years, Cerebras has been stuck at the bandwidth that NVLink had 10 years back! The incumbent is lapping the startup on innovation.
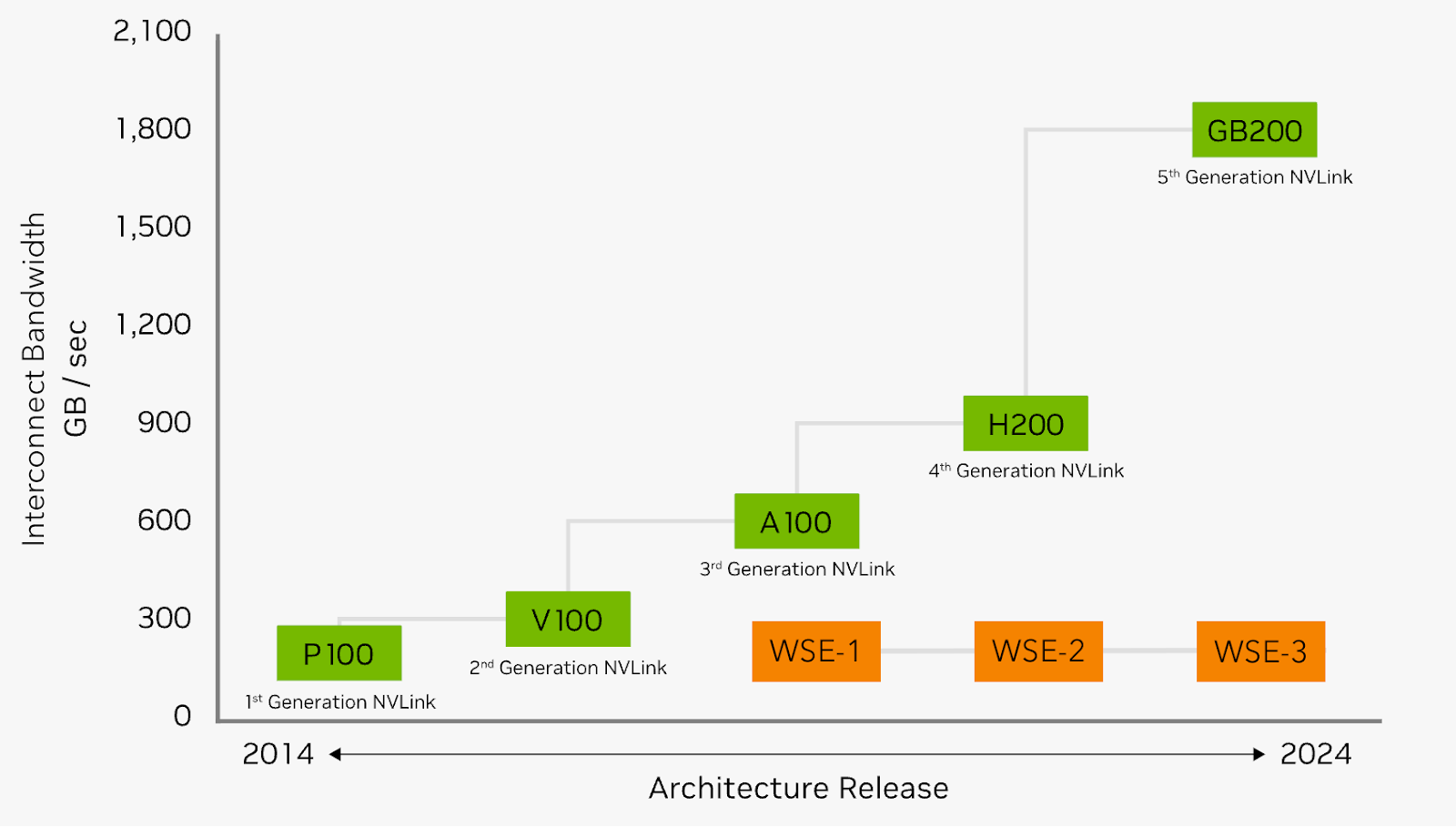
It doesn’t matter if WSE-3 can do math ops at twice the speed of WSE-2, if it can’t be fed data from the neighboring chip twice as fast.
But what if the model fits on one wafer, we don’t have to bother about being throttled by the 150 GB/s lane? Cerebras should have record-breaking speed in this case!
Unfortunately, I have more bad news for you.
Let’s look at 8B models. This model fits on a single WSE-3. We have Artificial Analysis, showing that Cerebras has created a world record by generating output tokens at 1850 tokens/s. The latest number, on the same website, seems to be 2196 tokens/s.
Now let’s bring up comparable numbers on a competitor. We have NVIDIA’s H200 numbers that they self-report on their website. Note that Cerebras’ numbers are for FP16, while NVIDIA’s are FP8. Cerebras is locked into FP16 because of chip design choices they made. Cerebras provided numbers for input token lengths of 100, 1000 and 10000. Hence we are picking the closest matches from NVIDIA’s benchmarks. Output length has not been specified by Artificial Analysis, but we can infer based on the notes in the graphs, it is 100. See why it would help if everyone would just go to MLPerf?

Take a look and remind yourself that we are comparing a $2.5M WSE-3 to a $40k H200.
It isn’t even close.
To summarise, Cerebras is getting thoroughly beat even if the model is small enough to fit on a single wafer. If the model is so large that it needs more than one wafer, the margin of the defeat will be much larger. The competition is faster and cheaper, in both cases. There’s no doubt about it.
For Cerebras, I really do not grasp the point of playing marketing games on make-believe metrics with an incumbent who generates more free cash flow per quarter than the last known private valuation of the company. One of these days, Jensen is going to wake up and choose marketing violence, and that would be embarrassing for Cerebras.

Can Cerebras be a vertically integrated cloud company?
When chip companies start to offer cloud, there are two possible reasons
Customers have very little appetite to buy their chips because they are unproven overall and uneconomical for their use. They would prefer that someone else take the risk of capex. So the chipmaker has to raise capital, host their own chips and allow the customers to use it through a cloud offering.
The cloud offering is a short term loss leader to cross the hurdle of adoption. But the endgame is to earn customers’ trust so that they can summon the courage to buy your chips in time.
Chip companies can say they will capture more margin that they are losing by selling to cloud providers who then turn around and allow customers to use their chips. This is a rather strange claim because cloud providers like AWS and Google Cloud want to make their own chips to increase their margin that they lose to NVIDIA. Between chip companies and cloud providers, the former has higher margins. For example, Broadcom makes 65%, AWS makes 32%.
Now, as a chipmaker, you could make the argument that if you
have paid for and deployed your own chips
taken care of all the software specific to your chip offering
allowed the user to interact with your chips through your cloud product instead,
that is the end of the debate about total cost of ownership. Since your customer is on a pay-per-use contract, what does it matter how much the chips cost to own and maintain? This strategy is now being explored by all 3 major ML hardware startups (Groq, Cerebras and Sambanova).

Let’s examine this strategy further. As long as you have transparent pricing, the customer will be able to calculate their ROI from paying the per use price that you offer. In principle, this reduces friction of initial customer adoption. Hopefully, it builds familiarity with your offering and in the future, you can convince folks to buy the chips directly because now you have champions.
A true vertical cloud company is hard to build! A cloud company entails creating a robust software ecosystem that allows a customer absolute freedom to innovate on top of hardware I can rent. Look at this page for example: Cirrascale. Click through the offerings under Cerebras and those under NVIDIA. That’s the difference between having absolute freedom with the underlying hardware and being restricted - you can only do certain things. What the trio of Groq, Cerebras and Sambanova are providing today are API endpoints. You can deploy a public model, without fine-tuning and get your output by calling the API. It is up for debate and in time the market will settle it, but my current contention is high value use cases are unlikely to live under these restrictions that limit rate of iteration and experimentation at the speed of customer intent. If I am going to need Cerebras engineers to help me deploy or finetune my model everytime, I think I will move to GPUs where I can move as fast as I want.
Moreover, abstracting the capex away from the customer, in turn, raises questions about the financial viability of the chip company. What does it do to the capital efficiency of the chipmaker? What was supposed to be the deployers’ expenses (capex, opex, maintenance) is now shifted on to the balance sheet of the chipmaker. Cerebras’ overall margins are already quite low for a chipmaker. The industry standard is 65%+. They are currently at 45%. How will it look as a vertical cloud company?
Worse.
I am taking some liberty with simplification, so point out errors in my reasoning. We know that Cerebras hardware margins were 20% for the year of 2023 and 36% for half year of 2024. Let’s be generous and assume that 36% is the ongoing margin. I am loosely inferring from this, a WSE-3 which sells for $2.5M has cost Cerebras $1.6M to make. Let’s assume a hyperscaler buys one DGX B200 from NVIDIA for $500k. We can say with a high degree of certainty that in a head-on comparison, the customer will be able to see the same tokens/sec from the hyperscaler, if not much higher. Assume that the useful life of GPUs and WSE-3s are the same. Also assume that both can serve the same number of customers with acceptable speeds - this is not true, and Cerebras is weaker here, but bear with me for simplicity. Just to break even, Cerebras will have to charge thrice what GPU-based hyperscalers can. Anything lower and they are losing money on each inference call. That means lower overall margins as a company.
How can this improve? Cerebras desperately needs customer adoption. More customer adoption will lead to more chips being needed, which in turn will lead to them being able to negotiate better prices with TSMC. But the two forces are opposed - more wafers brought in house mean more opex but possibly lower prices. It would be interesting to see how this plays out.
But if you are building a cloud offering on this, undercutting the market by offering a lower price for inference, all while carrying a much higher capex, added opex, who is eventually paying for the difference? Future shareholders - via capital raises through more dilution, which means lower stock prices in the future.
What does the nature of future workloads bode for Cerebras?
There has been a lot of talk about how big the inference market would be. DeepSeek wreaked havoc in early January. A lot of opinions were shared about how incumbents have a weaker positioning compared to startups who have been building for this moment.
Let’s examine those claims.
First, learn a new term - batch size. Batch size determines how many inputs a model processes in parallel.
Batch sizes and utilization
A general truth is that GPUs are slow for batch size = 1 but fast for batch size = n. Cerebras is great for batch size = 1, but not for batch size = n.
At batch size = 1, LLM outputs are bound by the constraints of memory bandwidth. The chip is ready to do the math required, but is essentially “waiting” for all the model weights to be streamed in from the memory. In Cerebras’ case since the time to load the weights from co-located memory is shorter, we can expect them to be fastest. But this flips when there are many jobs (representing batch size = n). Now you can take advantage of the parallel architecture of GPUs. The time to stream the model weights onto the chips is a one-time event and you get to amortize this across many users who are calling the API at the same time. But your output is now constrained by how much compute you have available. As we saw earlier, Cerebras has much lower compute available compared to NVIDIA. Furthermore, larger batch sizes also mean you need to use multiple wafers in Cerebras - as discussed earlier, that is the weakest link in their tech stack.
Any metric based on batch size = 1 is not a commercially relevant metric for the deployer. As such, if you see crazy high speeds of inference, a deployer should always question what batch size is the data being shown for. For the API user, you are free to enjoy your high-speed inference! If you are the deployer hosting the chips and offering API inference calls, you want maximum utilisation of your expensive asset. Otherwise your high speed inference token/s may as well be representing high speed depreciation per second.
In August 2024, Cerebras was asked to comment on their batch size. The response was “our current batch size # is not mature so we'd prefer not to provide it. The system architecture is designed to operate at high batch sizes and we expect to get there in the next few weeks.” Take a look at this conversation that took place in November 2024. Do you see an answer yet? In fact, whenever Cerebras has been asked if their data is for a commercially relevant batch size, they have responded somewhat like:

New models and agents
The source of excitement around new models like o1/o3 and, more recently, Deepseek was the demonstration that you can get higher-quality outputs if the model was allowed to “think”. Inference time-scaling, as it is called, showed that if you threw more compute at the inference stage, your output would be much better.
This creates more demand than ever anticipated previously. Essentially, a single prompt will now branch into multiple “chain of thought”, each being an inference call, while another additional layer of compute is needed to compare, analyse, synthesise and then present the user with the solution they requested.
This is the same for agentic workflows. You can think of each agent as multiple inference calls in themselves. There is also an increased need for speed. If a human was reading the output, it doesn’t matter if you are generating tokens much faster than human reading speed. But if an agent is, you want the highest speed you can afford, period.
What does this mean for the chipmakers?
If your offering is not competitive for high batch sizes, you can exit the race.
If your offering is not capable of high speeds at affordable prices, you can exit the race.
The inference market may be $100B or $10T, but without satisfying the above two conditions, you will only be able to grab a fraction of the market that can’t buy NVIDIA.
DeepSeek and Cerebras
Immediately after the DeepSeek-led frenzy, Cerebras, Groq and Sambanova went into PR mode and put out crazy speed demos. This would be a game-changer for the AI infra layer, they all said. I don't quite understand how. Nothing changed because of DeepSeek for the trio. Nothing about the model architectures make it a magical fit for any of these chip architectures, much less Cerebras’. If you were not competitive before, you are still not competitive now. A blog, written by Jeffrey Emmanuel, spread like wildfire, shared by accounts with distribution to millions of people, apparently playing a role in driving a $600B selloff for NVIDIA in a day. Ironically, the section on hardware threats is almost entirely wrong. There is no threat that is being posed by Groq or Cerebras to NVIDIA because of DeepSeek. The author seems to have fallen prey to the misleading comparisons of speed that both these companies put out.
If you bought the dip, you can thank Jeffrey for generating a flash sale on NVIDIA! You can absolutely get those same speeds with lower capex GPUs. The only problem is that hyperscalers want to make money while offering those speeds, while Groq and Cerebras have seemingly decided not to. They want to appear faster and cheaper than NVIDIA - both of which they are not.
The market has been giving us hints all along
Cerebras doesn't have any notable paying customers who have declared the company's solutions critical to their business. Yes, I am aware of the collaboration with Mistral and running Sonar for Perplexity. They are notable, but my emphasis is on the word, “paying.” In both these cases, Cerebras is running the cloud offering for them. Being able to call Mistral or Perplexity partners gets you immediately noticed by investors, which is fantastic ahead of the IPO. Something very interesting happened with regards to the PR around the announcement. Cerebras put out the announcement that Perplexity is “moving” to Cerebras on the afternoon of Feb 11. I questioned the whole thing in the evening of Feb 11. On the morning of Feb 12, the CEO of Perplexity put out a strongly worded tweet saying that they were not involved in and do not approve of the language used by Cerebras team. I draw your attention to two things - the criticality of dependance on NVIDIA and the explicit claim that “Cerebras or Grok are not robust chips that can handle both dense models and sparse MoEs yet.”
(Sidenote - if Cerebras was a public company, this kind of tweet would have invited litigation. Lucky for them, they are not.)It is not a good look for an AI hardware company to list mostly academic/national labs amongst its US/EU customers. We need to recognise that government labs are encouraged to buy alternatives to the best hardware if buying the best may create or reinforce monopolistic trends. Assuming an average price of $2.5M, excluding G42 sales, Cerebras seems to have sold roughly 14 units in the last 2 years. Most of these are to government/academic entities.
Cerebras’ initial claim was that they would put a datacenter in a rack. Well, it is 2025 and their potential customers are literally talking about multi-datacenter training and yet they would not buy Cerebras.
Despite having Sam Altman as an investor, OpenAI has said nothing about Cerebras. It is markedly important that even RainAI, a significantly smaller and less mature hardware company, was raising money based off an $51M LOI from OpenAI in 2019. In fact, Sam is now helping RainAI raise $150M on a $600M valuation. The mismatch between what Cerebras offers and what OpenAI needs is so large that Sam Altman would rather hire engineers, work with Broadcom and TSMC and make a new chip, than buy Cerebras.
Meta is making MTIA. They are working on an acquisition of FuriosaAI in South Korea. Amazon is making Trainium. These are all 10s of billions worth of investments. If Cerebras was a competitive offering, they would surely do something with them, wouldn’t they?
The big realisation
Imagine you meet a company who say they
had 87% revenue come for a customer in the middle east (G42), who were most likely buying the product because they couldn’t buy their first choice
had to incentivise the customer to buy the product by giving them discounted shares in the company (and future shares if they buy more),
didn’t have any notable paying customers in the US/EU and
were losing money every time someone used their cloud offering
Would you think, yeah, you should IPO?
In startups, we often attach a premium if you can create a captive customer base. In this case, the customer has the company captive. If G42 pulls out, there would be serious trouble.
So here’s the answer to the question we asked in the very beginning.
Cerebras doesn’t have product-market fit.
Not at these specs, not at this price, not for these use cases.
Yes, I know I am saying this about an IPO candidate which has raised money from marquee investors and has made about $200M cumulative revenue.
It doesn’t matter how creative, beautiful or elegant the engineering of your offering is. The only way to challenge a dominant incumbent is with technology that is truly disruptive along the axes that matter to the customer. You can’t cherry pick make-believe metrics and expect the market to come along for the ride. It will, simply, not work out.
Why IPO at all?
Generally, in this red-hot AI market, an AI hardware company going to IPO on supposedly exploding revenue growth but still at a few hundred millions of actual revenue, must have been turned down by private capital providers on their proposed terms. Databricks is floating a $8B private tender to allow employees cash out if they want to. This would be for a company that is slated to make $2.4B revenue in the first half of the year, well past the $1B that has been stated as a necessary condition to IPO in this market. That is a proof of demand from institutions that think there is a growth path that would allow them to have a multi-bagger if they took positions in Databricks at $61B valuation (~12X multiple on revenue). Anduril is working on a round at a $28B valuation, Stripe is doing tender after tender, staying private longer while institutional capital providers get pre-IPO ownership. SpaceX is following the same path. Given the risks that are now apparent to me, I think Cerebras is looking for a valuation that its product offerings’ market positioning doesn’t support.
The deal with G42 doesn’t inspire confidence. What does it signal about the strength of the product offering if 87% of your revenue comes from one customer (which happens to be a regional compute provider, outside of major compute-hungry geos, in an GPU export-restriction affected geo) and you have to offer your customer the option to buy discounted shares in the company if they purchase product from you?
There’s more weirdnessThe series F round priced each share at $27 in Oct 2021. G42 has an option to purchase $335M worth of shares at $14.66 a piece before April 20, 2025.
Furthermore, if G42 buys or directs someone else to buy more product between 500M and 5B, they get to buy shares at a 17.5% discount worth 10% of the purchase order amount.
More thoughts on the G42 deal
What does G42 want with Cerebras anyway?
The answer is hidden in a paragraph in NVIDIA’s 10Q filed in Aug 2023.
“During the third quarter of fiscal year 2023, the U.S. government, or the USG, announced license requirements that, with certain exceptions, impact exports to China (including Hong Kong and Macau) and Russia of our A100 and H100 integrated circuits, DGX or any other systems or boards which incorporate A100 or H100 integrated circuits. During the second quarter of fiscal year 2024, the USG informed us of an additional licensing requirement for a subset of A100 and H100 products destined to certain customers and other regions, including some countries in the Middle East.”
The deal between G42 and Cerebras happened in July 2023. Given the timing, I speculate that Cerebras is G42’s backup option. In a way, this is also a tacit admission that they expect NVIDIA chips to be regulated but not Cerebras. Why? Is it because it is not so critically important? What effect does this have on Cerebras’ positioning and pricing power?
This IPO is literally supported by this cash injection from G42. If I am reading it right, G42 is responsible for $183M out of the $240M revenue that Cerebras has done between 2022 and 2024. If you take that revenue away, Cerebras has not even crossed $60M (from 2022-24). I am not certain if G42 is buying Cerebras because they like to buy expensive chips that are also slow, or because they can’t be sure they can buy as much NVIDIA as they want to, when they want to. I am kidding, of course. I know, it is the latter.
I also had a stray thought about what would make G42 pull their commitment. There have been reports that Huawei Ascend 910c can give 60% of NVIDIA’s performance on DeepSeek. Huawei has free rein in the middle east. It has been inferred that a Ascend 910c unit costs $28k. Information about Huawei performance should be taken with a grain of salt, again because they are not publicly benchmarked. But if G42 has access to reliable data, I would be very surprised if they aren’t currently reviewing why they want to pay so much more for Cerebras.
Where do we go from here?
There are many technical achievements for which Cerebras deserves a lot of credit. In fact, I truly believe they will be studied as a pioneer for this chip architecture. How do you deliver power vertically, how do you cool this mammoth chip down, how do you draw your cross-die scribe lines - these are all amazing engineering feats. The lessons from Cerebras would inform the design of new chips in the next 5-10 years as their alumni start new companies or others get inspired. I think this IP is crucial, and it is in our best interests to make sure we never lose it.
Commercially, I don’t see Cerebras as a serious challenger in the AI market - training or inference - in the short to medium term unless
There is some new model architecture absolutely different from everything that we are seeing which beats all current models and is also somehow a great fit for their hardware architecture. For example, no one has figured out a generic way of using sparsity to meaningfully accelerate training or inference. If there is a breakthrough on this line, Cerebras is better positioned because then the 10X difference between dense and sparse compute is a much higher step up than NVIDIA’s 2X step up. In that case, we will really be getting the full 125 petaflops of peak AI performance out of a WSE-3, compared to a 32 petaflop from a DGX B200.
There is a subset of customers on the market for whom low latency is so important that they would take a giant hit on overall speed and cost for it.
The problem is that the company has been priced as if it is a prime challenger for the gen AI era. In my assessment, Cerebras has very little chance of being able to grab that mantle with the trajectory they are on. However, I don’t think Cerebras needs to be an AI hardware company right away. Maybe the offering will have better ROI for customers who run a lot of simulations where supercomputers have traditionally been used - simulations of physical or biological phenomena, for example. I have not thought about this in too much detail but I intend to.
I hope they don’t go public. But if they do, it is not impossible that there’s an initial surge in demand due to the current enthusiasm surrounding AI. A whole bunch of capital is looking for ways to gain exposure to the AI wave. I will feel really stupid for not buying when this happens. It has been discussed by many that the hardware layer may be one of the most reliable investments through this cycle. However, I anticipate this momentum to wane once Cerebras transitions into a public company, subject to increased scrutiny and disclosure requirements. Public market analysts are a different breed than VC sweethearts. The release of company data will, in most likelihood, not meet market expectations, potentially triggering a souring of investor sentiment. I have written about why I think this would be dangerous.
I am looking for Cerebras’ tech roadmap to start reflecting some of the real challenges that they need to solve:
More dense FLOPs
Higher speed I/O
Unmistakable demo of speed-up over competition, no gimmicks.
Without making real progress on these, I am afraid, this NVIDIA challenger is not even in the same arena.
Why does it have to be this way? Can we not try the following?
Align with the founding team on what really needs to get built to hit metrics that are important to customers - real ones that you can benchmark against incumbent offerings.
Recapitalise the company, take a down round from investors with longer time horizons, involve UHNWI family offices perhaps. There are plenty of companies that raised at crazy valuations in the ZIRP era. In time, if you become the next NVIDIA, no one’s going to complain.
Whoever wants to go public can take a giant haircut and leave. They are pushing the company to do these marketing stunts which is distracting from true technical progress.
No media tours, press releases and marketing until technical milestones are hit. Stay out of public markets and scrutiny until you can dazzle.
I believe this company has the potential to become a truly generational offering but they need time and privacy. Public markets will give them neither.
Please make the hard choice. Don’t go public.